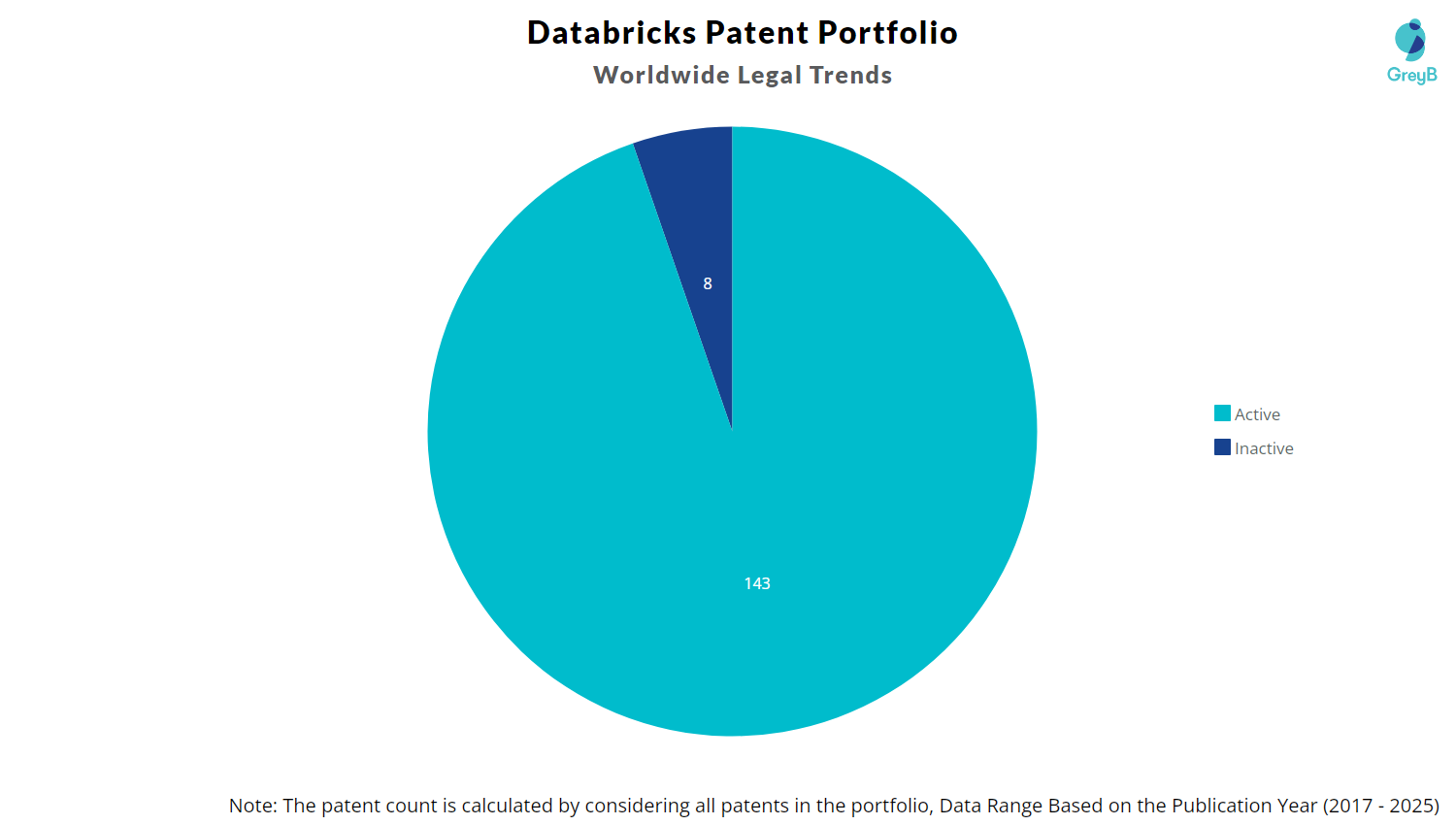
Databricks has a total of 151 patents, out of which 94 have been granted. Of these 151 patents, more than 94% patents are active. The United States of America is where Databricks has filed the maximum number of patents followed by Europe (EPO) and Canada. Parallelly, United States of America seems to be the main focused R&D center of Databricks and also USA is the origin country of Databricks.
Databricks was founded in the year 2013. The company provides software solutions and develops software platform that helps its customers unify their analytics across the business, data science, and engineering. Databricks serves customers worldwide.
Do read about some of the most popular patents of Databricks which have been covered by us in this article and also you can find Databricks patents information, the worldwide patent filing activity and its patent filing trend over the years, and many other stats over Databricks patent portfolio.
How many patents does Databricks have?
Databricks has a total of 151 patents globally. These patents belong to 81 unique patent families. Out of 151 patents, 143 patents are active.
How many Databricks patents are Alive/Dead?
Worldwide Patents
How Many Patents did Databricks File Every Year?
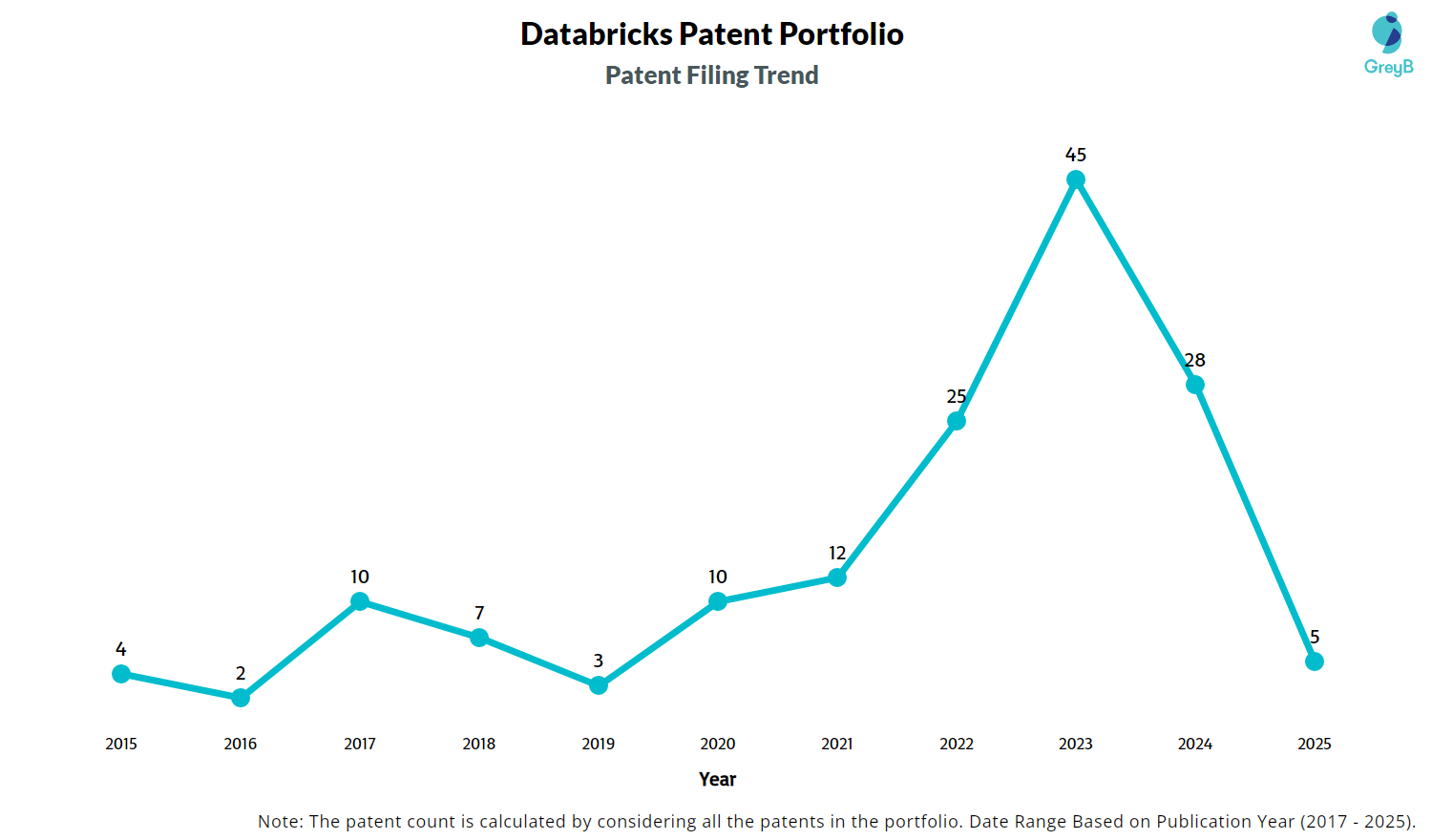
Are you wondering why there is a drop in patent filing for the last two years? It is because a patent application can take up to 18 months to get published. Certainly, it doesn’t suggest a decrease in the patent filing.
| Year of Patents Filing or Grant | Databricks Applications Filed | Databricks Patents Granted |
| 2025 | 5 | 31 |
| 2024 | 28 | 25 |
| 2023 | 45 | 12 |
| 2022 | 25 | 7 |
| 2021 | 12 | 2 |
| 2020 | 10 | 6 |
| 2019 | 3 | 4 |
| 2018 | 7 | 3 |
| 2017 | 10 | 4 |
| 2016 | 2 | – |
| 2015 | 4 | – |
How Many Patents did Databricks File in Different Countries?
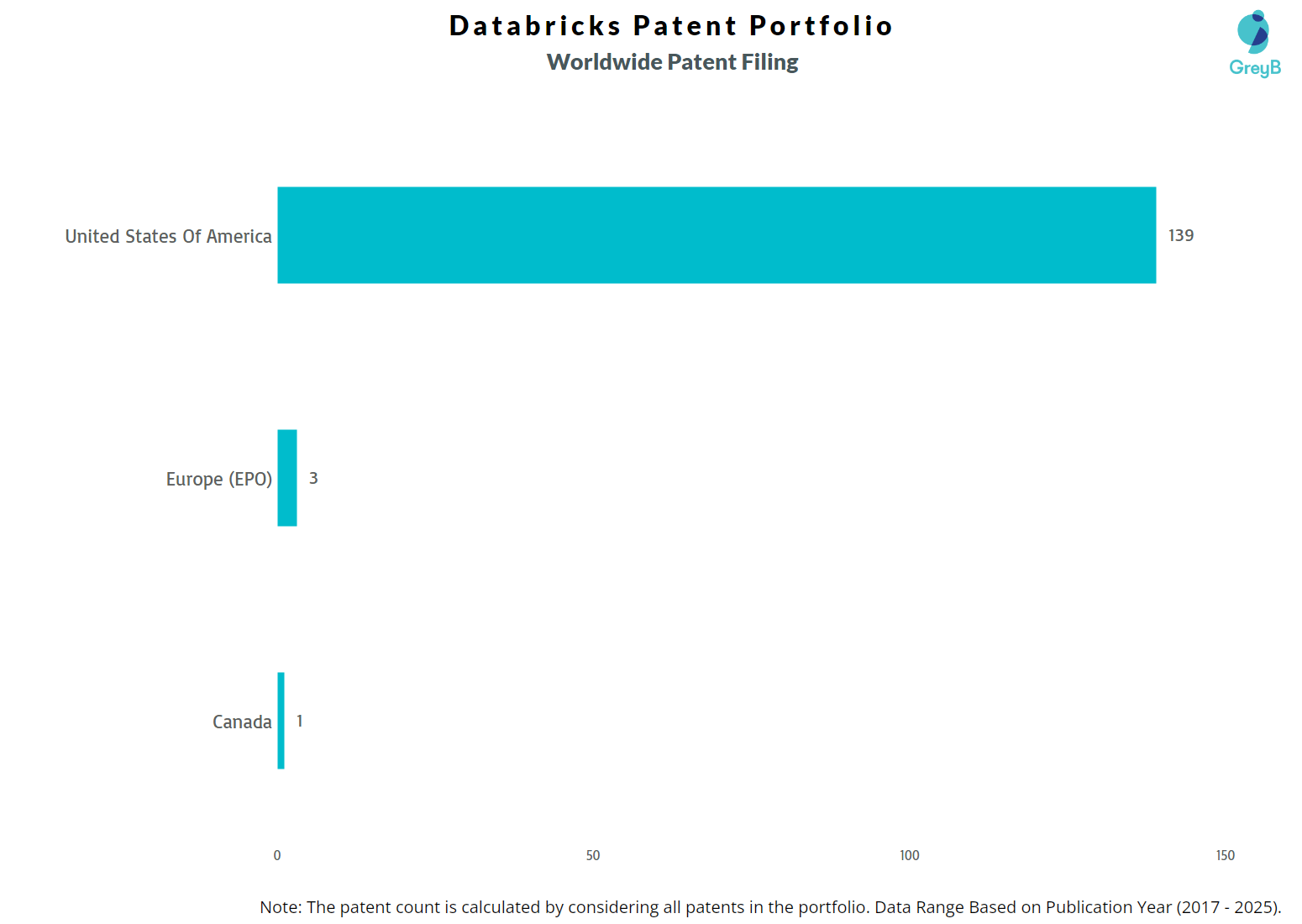
Countries in which Databricks Filed Patents
| Country | Patents |
| United States Of America | 139 |
| Europe (EPO) | 3 |
| Canada | 1 |
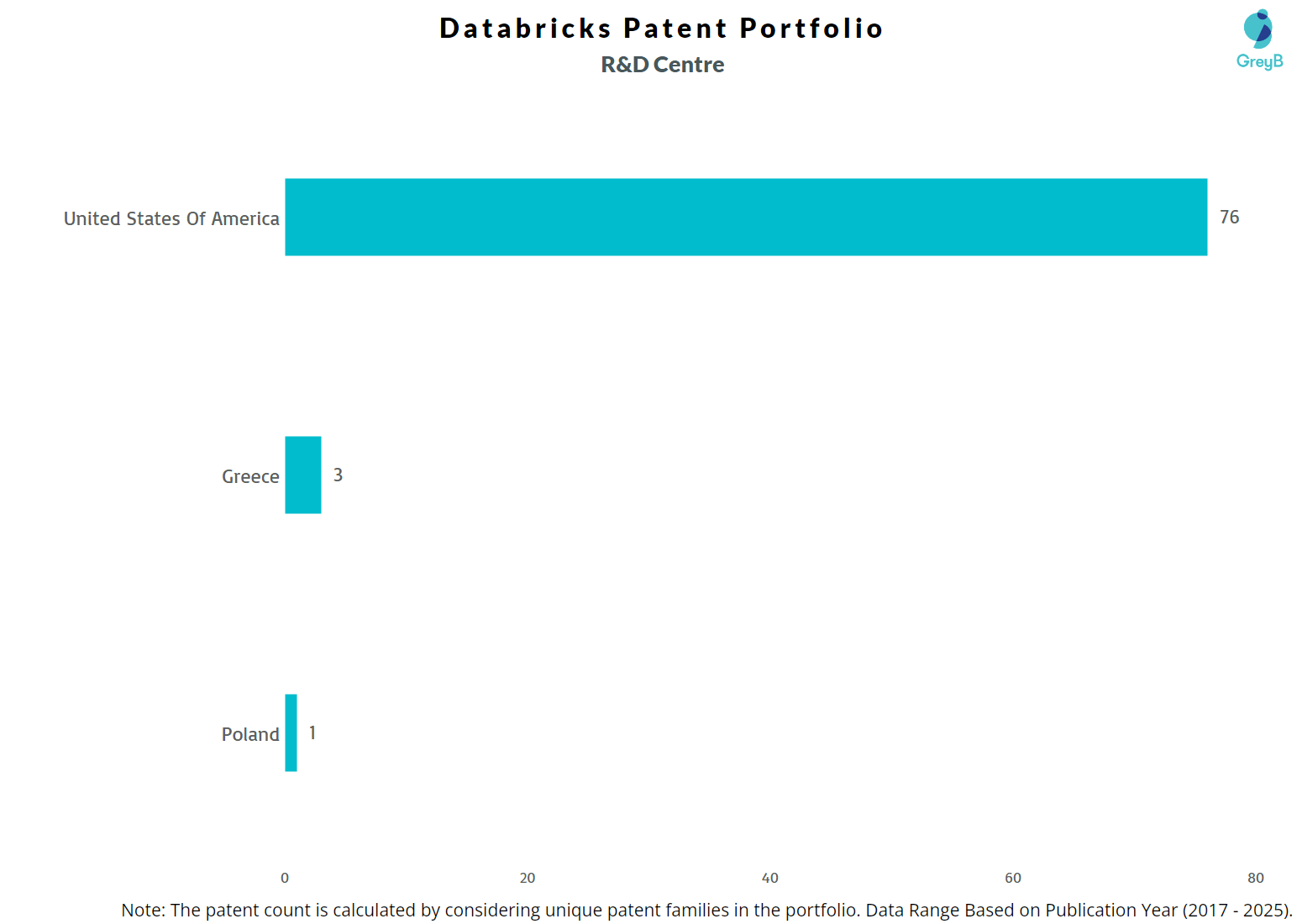
Where are Research Centers of Databricks Patents Located?
10 Best Databricks Patents
US10474736B1 is the most popular patent in the Databricks portfolio. It has received 72 citations so far from companies like Data World Inc, and Microsoft.
Below is the list of 10 most cited patents of Databricks:
| Publication Number | Citation Count |
| US10474736B1 | 72 |
| US10769130B1 | 67 |
| US9769032B1 | 53 |
| US10474501B2 | 47 |
| US10606675B1 | 46 |
| US9760602B1 | 46 |
| US9990230B1 | 45 |
| US10810051B1 | 43 |
| US10691433B2 | 43 |
| US10678536B2 | 43 |
What Percentage of Databricks US Patent Applications were Granted?
Databricks (Excluding its subsidiaries) has filed 76 patent applications at USPTO so far (Excluding Design and PCT applications). Out of these 54 have been granted leading to a grant rate of 100%.
Below are the key stats of Databricks patent prosecution at the USPTO.
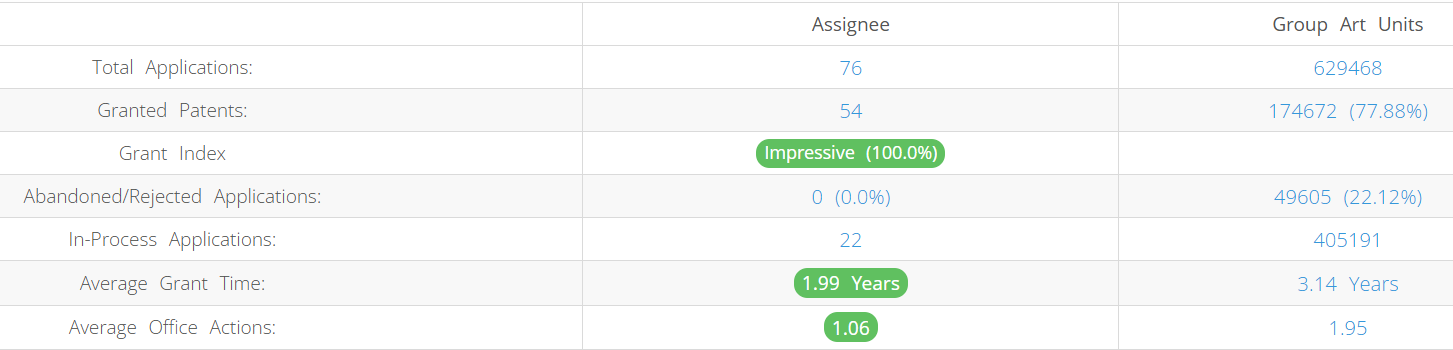
Which Law Firm are managing US Patents for Databricks?
| Law Firm | Total Applications | Success Rate |
| Fenwick & West Llp | 76 | 100.00% |
“Databricks takes the pain out of cluster management, and puts the real power of these systems in the hands of those who need it most: developers, analyst, and data scientists are now freed up to think about business and technical problems.” — Shaun Elliott
The use of data is at the heart of how these modern businesses are evolving. With this information, businesses can take advantage of AI’s promise to produce disruptive technologies that will influence practically every company on the planet. The problem most businesses confront is figuring out how to succeed with both data and AI.
The Unified Analytics Engine, Apache Spark
Enterprises are increasingly using Apache Spark to circumvent the challenges associated with walled data and diverse platforms for managing different analytic operations. Due to its record-breaking speed, ease of use, and support for advanced analytics, Spark, which was built by the founders of Databricks, has become the de facto standard for data processing and AI today. Spark makes AI data preparation easier by combining data from a variety of sources, including cloud storage systems, distributed file systems, key-value stores, and message buses, at a large scale. Spark also brings together data and AI with a consistent set of APIs for data loading, batch/stream processing, SQL analytics, stream analytics, graph analytics, machine learning, and deep learning, as well as seamless integration with popular AI frameworks and libraries like TensorFlow, PyTorch, R, and SciKit-Learn.

